The goal of {ppcryptoparser} is to simplify the import of staking reward from various altcoins into Portfolio Performance.
Installation
You need a working installation of R.
Windows: scoop install r or download from CRAN.
macOS: brew install --cask r or download from CRAN.
Ubuntu: apt install r-base
You can then install ppcryptoparser from GitHub with:
install.packages("remotes")
remotes::install_github("pat-s/ppcryptoparser")Example
Spin up an R session by calling “R” in a terminal and then run
Please also consult the help files for each function, either on the command line via ?<function name> or by looking at the pkgdown page of this package.
Supported Coins
- Cardano (ADA)
- Polkadot (DOT)
- Kusama (KSM)
- Solana (SOL) - API Key needed!
Language & Currency
The default language is set to (US) English ("EN"). The language setting should match the language used in Portfolio Performance.
Viewing statistics in Portfolio Performance
Staking statistics for inbound deliveries can be viewed under “Payments -> Savings” (German: “Zahlungen -> Ersparnisse”). To only see the staking rewards in this menu, you need to book the staking rewards to a dedicated depot which only contains the staking rewards. Then you can select this depot via the filter option. Otherwise, when selecting your complete portfolio, also buy actions will be included in this overview and blur the statistics.
Encoding & Windows
I’ve seen that on Windows machines, the encoding might be set to something else than “UTF-8”, causing issues in the processing.
Also Windows seems to set the decimal separator to . instead of ,, which causes a wrong import of the data. In this case, edit the resulting .csv file and change the decimal separators from , to . and check whether the import is working as intended. I might add an argument to the functions to account for this within the R package.
CSV Import
When importing, ensure to choose the type “Depotumsätze” / “Portfolio Transactions”:
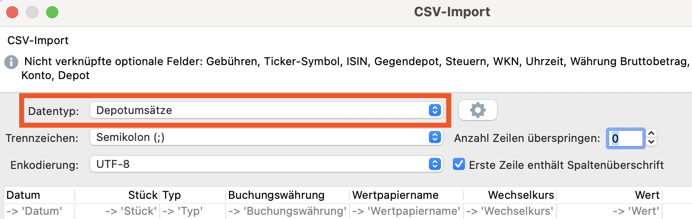
Screenshot showing how to import CSV
Coin-specific Infos
Kusama
Kusama pays out rewards every six hours. parse_kusama() comes with an argument `“by_day” which aggregates rewards by day.
Solana
Solana data is queried from https://solanabeach.io which requires an API key. Instructions how to ask for an API key can be found on their GitHub README.
Solana staking account cannot be topped up, hence often more than one staking account exists. parse_solana() is able to account for this by merging the rewards from multiple addresses. To do so, one needs to pass the addresses as a vector like this
parse_solana(c("<address1>", "<address2>"), by_day = TRUE)